
We formulate UAV navigation as an iterative target-reaching process in 3D space. At each timestep $t$, the system processes the current visual observation $I_t \in \mathbb{R}^{H\times W\times3}$ along with a natural language instruction $\ell$ to determine the next motion. Our approach leverages vision-language models (VLMs) to transform navigation instructions into interpretable waypoint decisions that can be efficiently converted into UAV control signals.
The system operates through three key stages: (1) Given $\ell$ and $I_t$, we use a VLM to produce structured spatial understanding, predicting 2D waypoints and step sizes; (2) We transform the predicted 2D waypoint into 3D displacement vectors, yielding executable low-level commands; (3) A lightweight reactive controller continuously updates observations and executes motion commands in closed-loop manner.

Pipeline Overview: A camera frame and user instructions enter a frozen vision-language model, which returns structured JSON with 2D waypoints and obstacle information. An Action-to-Control layer converts this into low-level velocity commands for the UAV.
VLM-based Obstacle-Aware Action Planning
We frame this stage as a structured visual grounding task, where the VLM $G$ processes an egocentric UAV camera observation $I_t$ alongside a natural language instruction $\ell$. The VLM outputs a spatial plan $O_t = \{u, v, d_\text{VLM}\}$ specifying a navigation target in image space, where $(u, v)$ are pixel coordinates and $d_\text{VLM} \in \{1, 2, \ldots, L\}$ is a discretized depth label representing the intended travel distance.
The key insight is that $d_\text{VLM}$ represents the VLM's prediction of appropriate movement magnitude along the UAV's forward direction, rather than a sensored depth measurement. When obstacle-avoidance is activated, the VLM generates waypoints that guide the UAV toward the goal while avoiding detected obstacles, enabling safe navigation through cluttered environments.
Adaptive Travel Distance and 3D Transformation
To address the limitation that VLMs may lack precise understanding of real-world 3D geometry, we employ an adaptive scaling approach. The discrete depth label $d_\text{VLM}$ is converted into an adjusted step size using a non-linear scaling curve:
This enables the UAV to take larger steps in open areas while executing smaller, more cautious movements near targets and obstacles. The predicted 2D waypoint $(u, v)$ and adjusted depth $d_\text{adj}$ are then unprojected through the camera model to obtain a 3D displacement vector $(S_x, S_y, S_z)$, which is decomposed into control primitives: yaw, pitch, and throttle commands.
By outsourcing high-level spatial reasoning to the VLM and employing a lightweight geometric controller, our method achieves robust zero-shot UAV navigation directly from language—without relying on skill libraries, external depth sensors, policy optimization, or model training.
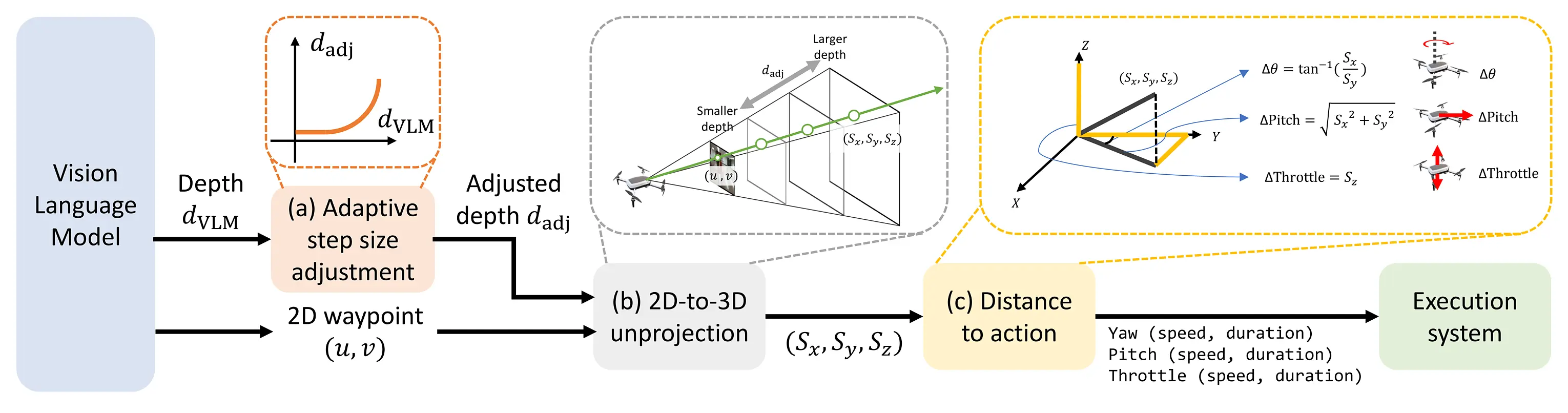
Method Details: Our approach transforms 2D waypoint predictions into 3D displacement vectors through geometric projection, with adaptive step-size control for efficient navigation.















